
![]()
⚡️ Tópico: Breed Classification with Pytorch Lightning
En este post, resolveremos un problema clásico de Machine Learning: Clasificación. Lo interesante, es que no será un problema tabular, si no que será un problema de Computer Vision 👁️. Esto quiere decir que utilizaremos modelos de Deep Learning para clasificar imágenes dentro de un set de categorias (o clases) pre-definidas. Si bien es un problema clásico, el hecho de que la entrada de nuestro modelo sean imágenes hace todo el tema mucho más motivante, y es un buen punto de partida para escalar y luego resolver problemas tales como: Object detection, Segmentation, Image generation, entre otros.
🔎 Motivación: Find your pet
Imaginemos tenemos una página web en donde las personas pueden subir carteles de sus mascotas perdidas, y a la vez carteles de sus mascotas encontradas. Una característica importante en tu página web sería tener un buen algoritmo de recomendación que logre hacer match entre estas mascotas. Algo que podría ayudar, es poder identificar correctamente la raza de la mascota (a veces los usuarios no saben de que raza es su mascota).
De hecho, el modelo que elaboraremos aquí puede servir para más que simplemente identificar la raza de la mascota. No pretendo profundizar en esto, pero en realidad nuestro modelo podrá utilizarse para generar Embeddings, i.e formas de representar una imagen vectorialmente en una dimensión menor. Esto puede ser utilizado directamente en sistemas de recomendación, recomendando aquellas mascotas encontradas que tengan embeddings cercanos a el embedding de la mascota que estamos buscando. Disclaimer: esto por sí sólo podría no ser un muy buen recomendador porque probablemente sólo recomendará mascotas de la misma raza. Si no entendiste este párrafo, no te preocupes, no es el tema principal de este post. Aún así, te recomiendo estudiar sobre que son los Embeddings!
🧠 Solución: Crear un modelo de clasificación de imágenes para detectar si una imagen corresponde a: Alguna raza de perro, gato o ninguno.
🔨 Tool Path: Que utilizaremos
A continuación les dejo las herramientas que utilizaremos en este post:
- Pytorch: es una biblioteca de código abierto para el desarrollo de aplicaciones de aprendizaje profundo y la investigación en inteligencia artificial.
- Pytorch Lightning: es una extensión de PyTorch que simplifica y estandariza el proceso de entrenamiento y desarrollo de modelos de aprendizaje profundo en PyTorch, facilitando la creación de código limpio y modular.
- Weight and Biases: plataforma que permite realizar un seguimiento, visualización y colaboración en proyectos de Machine Learning.
- Timm: biblioteca que proporciona una amplia variedad de modelos de redes neuronales pre-entrenados para tareas de computer vision en PyTorch.
- Gradio: facilita la creación de interfaces de usuario interactivas para modelos de Machine Learning.
💭 Concept Path: Que aprenderemos
A continuación algunos de los conceptos que veremos:
- Convolutional Neural Networks
- Transfer Learning
- Data Augmentation
- Early Stopping
- Learning rate scheduling
La mayor parte de estos conceptos los explicaré en un bajo nivel de detalle, creo que existen múltiples recursos en internet con un muy buen nivel de detalle y explicabilidad de estos conceptos. Pero como siempre, si sientes que te gustaría profundizar en algo, charlemos!
♟️ Estrategia: Como abordamos
Al ser un clásico problema de ML, procederemos como se acostumbra:
- Recolectar datos: Buscar nuestras imágenes y sus respectivas etiquetas.
- Definir una linea base: Un modelo fácil y rápido.
- Aplicaremos otros modelos (usualmente más complejos): Creamos un benchmark para nuestro caso de uso.
- Iteramos: Iteramos aplicando distintas técnicas, buscando mejorar nuestros resultados.
- Deploy: Desplegamos nuestra aplicación para que sea utilizada por el público.
Claramente existen otros pasos importantes, pero que no vienen al caso. Ej: Estudio de negocio, de factibilidad, de datos, etc.
🧠 Prototyping
Recordar que en esta ocasión utilizaremos Pytorch Lightning. Esta herramienta es un wrapper de Pytorch, que nos permite reducir la duplicidad de código y aumentar la modularidad. En otras palabras, es más fácil crear las rutinas de entrenamiento.
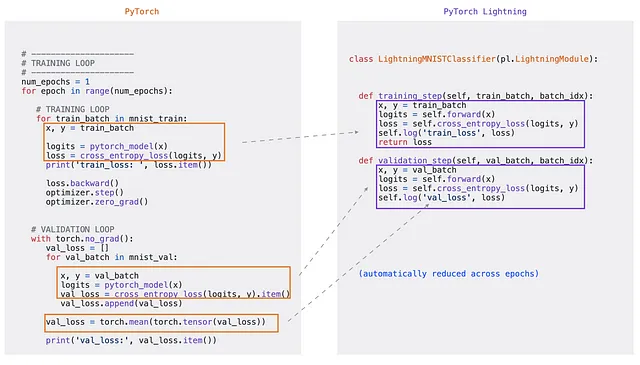
Fuente: https://towardsdatascience.com/from-pytorch-to-pytorch-lightning-a-gentle-introduction-b371b7caaf09
En resumen, Pytorch Lightning hace por nosotros un montón de cosas como: el loop de epochs, utilizar gpu o no, calcular o no gradientes, computar métricas a través de cada paso, etc.
Aún así, lo que necesitamos es muy similar a lo que se necesita en Pytorch puro. Esto es:
- Una clase Dataset: clase que facilita el acceso a la data. En este caso, a las imágenes.
- Un Dataloader: La forma en como los datos son cargados al momento de entrenar.
- Una clase Modelo: Acá indicamos de que se compone nuestro modelo, las capas que utiliza, el optimizador, la predicción, etc.
- Todo lo anterior es utilizado en la clase Trainer de Pytorch Lightning. La cual se preocupa de hacer toda la rutina de entrenamiento por nosotros!
A grandes rasgos, todo el proceso debería ser algo como:
import torch
# 1. Dataset
class MyDataset:
"""
Como consulto mi dataset?
"""
pass
dataset = MyDataset()
# 2. Dataloader -> como cargo mis datos
dataloader = DataLoader(dataset)
# 3. Modelo
class MyModel:
"""
Cual es la arquitectura de mi modelo?
Cómo pasan las imagenes através de mi modelo?
"""
pass
modelo = Mymodel()
# 4. Trainer
trainer = Trainer() # Algunas configuraciones de entrenamiento
# 5. Fit
trainer.fit(modelo, train_dataloader, val_dataloader) # Entrenamiento
# 6. Evaluate
trainer.evaluate(modelo, test_dataloader)Config
Normalmente, se utiliza un archivo, clase, etc. para definir la configuración general de nuestra aplicación. Por ejemplo: el nombre del modelo que utilizaremos, la ruta a la imagen, la ruta a el archivo de etiquetas, etc.
Por ahora, nuestra clase config será:
class CFG:
IMG_PATH = 'PATH/TO/IMAGES' # Ruta a imagenes
LABEL_PATH = '/PATH/TO/labels.csv' # Ruta a archivo de etiquetas
# Data
TEST_SIZE = 0.2 # Tamaño del conjunto de test
VAL_SIZE = 0.1 # Tamaño del conjunto de validaciónA medida avancemos, iremos agregando cada vez más variables.
1. Dataset
Al ser un problema supervisado, necesitaremos imágenes y sus respectivas etiquetas. Un dato freak, es que este proyecto ya lo habia resuelto hace unos años utilizando Tensorflow. En esa ocasión me tomé el tiempo de recolectar datos de distintas fuentes para construir el dataset final, para mayor información de como lo hice (no es tan importante), leer aquí.
TLDR: extraje una base de datos de Stanford de razas de perro, un dataset de Kaggle de gatos, y descargué manualmente algunas imágenes pseudo-aleatorias (otros animales, personas, cosas, paisajes). Juntando todo esto creé un dataset con las siguientes clases:
- 120 razas de perro
- Gato
- No detectado
Lo que tenemos, es una carpeta con cientos de imágenes. Además, tenemos un archivo .csv que nos indica la clase según el nombre de la imagen. Esto nos será util para la construcción de la clase personalizada Dataset en Pytorch:
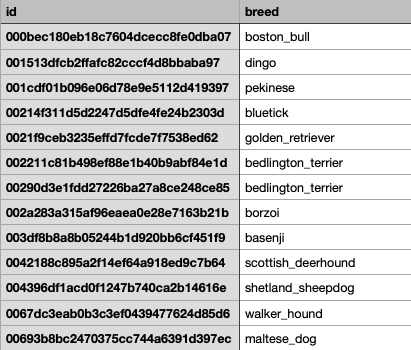
Todas las imágenes son jpg, por lo que la extensión la agrego en el código. Algo importante a mencionar, es que este dataset está balanceado (o almenos, no preocupantemente imbalanceado). Por lo que tenemos una cantidad decente de imágenes para cada clase.
Split
Como todo problema de ML, necesitaremos dividir nuestros datos en entrenamiento, validación y testeo. Para esto, sólo necesitaremos dividir el dataframe de el archivo de labels, ya que este mismo será utilizando en el siguiente paso (Pytorch Dataset).
from sklearn.model_selection import train_test_split
# Leemos el archivo de anotaciones/etiquetas
labels = pd.read_csv(CFG.LABEL_PATH)
X = labels.id # Data (paths)
y = labels.breed # Target
# Split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=CFG.TEST_SIZE, random_state=13, shuffle = True, stratify = y)
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=CFG.VAL_SIZE, random_state=13, shuffle = True, stratify = y_train)
# Dejamos todo en un df para cada conjunto
train_labels = pd.concat([X_train, y_train], axis = 1).reset_index(drop = True)
val_labels = pd.concat([X_val, y_val], axis = 1).reset_index(drop = True)
test_labels = pd.concat([X_test, y_test], axis = 1).reset_index(drop = True)Pytorch Dataset
Code time 👨🏾💻 !
Para crear una clase Dataset personalizada en Pytorch, se necesitan 3 métodos fundamentales:
__init__: La función__init__se ejecuta una vez al crear una instancia del objeto Dataset. Inicializamos el directorio que contiene las imágenes, el archivo de anotaciones y transformaciones.__len__: La función__len__devuelve el número de muestras en nuestro conjunto de datos.__getitem__: La función__getitem__carga y devuelve una muestra del conjunto de datos en el índice idx dado.
- Hagamos esto de forma iterativa, en un paso 0 deberiamos tener algo como:
from torch.utils.data import Dataset
# Clase Dataset
class PetDataSet(Dataset):
def __init__(self):
pass
def __len__(self):
pass
def __getitem__(self, idx):
pass- Ahora, comenzaremos por el método
__init__, acá es donde se inicializa la instancia. Es en donde buscaremos definir los atributos a usar en los siguientes métodos (__len__y__getitem__). Básicamente, lo que necesitaremos son: las imágenes (o la ruta a donde están), y el archivo labels que nos dice la clase de cada imagen según su nombre.
Además verás un parámetro llamado transforms. Por ahora, imagina que esta es una función que le cambia el tamaño a la imagen. Esto es importante ya que no podemos alimentar al modelo con imágenes de distintos tamaños. Más adelante, veremos como esta función puede hacer mucho más que sólo cambiar el tamaño a las imágenes.
from torch.utils.data import Dataset
class PetDataSet(Dataset):
def __init__(self, config, labels, transform):
self.labels = labels # DataFrame de etiquetas
self.dir = config.IMG_PATH # Path de imagenes
self.config = config # Clase configuraciones**
def __len__(self):
pass
def __getitem__(self, idx):
pass__len__: Ahora debemos calcular el largo de nuestro dataset. Esto es directo, ya que será igual a la cantidad de filas de nuestro DataFrame labels.
from torch.utils.data import Dataset
class PetDataSet(Dataset):
def __init__(self, config, labels, transform):
self.labels = labels # DataFrame de etiquetas
self.dir = config.IMG_PATH # Path de imagenes
self.config = config # Clase configuraciones
def __len__(self):
return len(self.labels) # largo de dataset**
def __getitem__(self, idx):
pass- Finalmente, el método
__getitem__, el más complejo. Debemos asumir que la entrada será un indice, y necesitaremos que devuelva la imagen correspondiente (en pixeles), y su clase.
from torch.utils.data import Dataset
class PetDataSet(Dataset):
def __init__(self, config, labels, transform):
self.labels = labels # DataFrame de etiquetas
self.dir = config.IMG_PATH # Path a imagenes
self.config = config # Configuraciones
self.transform = transform # Transformaciones
def __len__(self):
return len(self.labels) # largo de dataset
def __getitem__(self, idx):
breed = self.labels.iloc[idx, 1] # Etiqueta desde dataframe
img_path = self.labels.iloc[idx, 0] # Nombre imagen desde dataframe
full_path = os.path.join(self.dir, f'{img_path}.jpg') # Path completo a imagen
image = read_image(full_path)/255 # Se lee y normaliza la imagen
img = self.transform(image) # Función que cambia el tamaño de la imagen
return img, breed # Se retorna la imagen y la clase**Para esto creamos un diccionario que le asignará un número entero (índice) a cada clase i.g dalmata → 0. Además crearemos un diccionario que según un número entero, nos indique a que clase pertenece i.g 0 → dalmata. Todo esto lo haremos en nuestra clase de configuración:
class CFG:
IMG_PATH = 'PATH/TO/IMAGES' # Ruta a imagenes
LABEL_PATH = '/PATH/TO/labels.csv' # Ruta a archivo de etiquetas
# Data
TEST_SIZE = 0.2
VAL_SIZE = 0.1
labels = pd.read_csv(LABEL_PATH) # leemos archivo de etiquetas
idx_to_class = dict(enumerate(labels.breed.unique())) # id -> clase
class_to_idx = {c:i for i,c in idx_to_class.items()} # clase -> id**Ahora nuestra clase dataset quedará como:
from torch.utils.data import Dataset
class PetDataSet(Dataset):
def __init__(self, config, labels, transform):
self.labels = labels # DataFrame de etiquetas
self.dir = config.IMG_PATH # Path de imagenes
self.config = config # Configuraciones
self.transform = transform # Transformaciones
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
breed = self.labels.iloc[idx, 1] # Etiqueta desde dataframe
class_id = self.config.class_to_idx[breed]** # Convertimos clase a número
img_path = self.labels.iloc[idx, 0] # Nombre imagen
full_path = os.path.join(self.dir, f'{img_path}.jpg') # Path completo a imagen
image = read_image(full_path)/255 # Normalización de la imagen
img = self.transform(image) # Función que cambia el tamaño de la imagen
return img, class_id # Se retorna la imagen y el indice de la clase**Voíla! Hemos terminado nuestra clase Dataset, sólo falta inicializarla.
train_dataset = PetDataSet(config = CFG, labels = train_labels, transform = train_transform)
val_dataset = PetDataSet(config = CFG, labels = val_labels, transform = test_transform)
test_dataset = PetDataSet(config = CFG, labels = test_labels, transform = test_transform)Ahora podemos consultar nuestra data, por ejemplo:
len(train_dataset) # -> nos entregará el largo del dataset
pixels, class_id = train_dataset[0] # nos entregara la información del elemento 02. DataLoader
El modelo no irá consultando nuestra data uno por uno, ni toda a la vez. En realidad, nosotros le iremos entregando nuestras imágenes en batches. Gracias a esto, nuestro modelo es más eficiente y evitamos cualquier problemas de memoria (imagina cargar un millón de imágenes a la vez en nuestra memoria RAM 💥).
from torch.utils.data import DataLoader
train_dataloader = DataLoader(train_dataset, batch_size=64, shuffle=True, num_workers = 1)
val_dataloader = DataLoader(val_dataset, batch_size=64, shuffle=False, num_workers = 1)
test_dataloader = DataLoader(test_dataset, batch_size=64, shuffle=False, num_workers = 1)Existen otras cosas que los DataLoader pueden hacer, pero por ahora con esto basta. Para mayor información visita la documentación.
3. Model
Para el modelo, utilizaremos una técnica llamada Transfer Learning.
Existe una gran variedad de modelos de Computer Vision, los más conocidos son las redes convolucionales. Por bastante tiempo esta técnica ha estado en el estado del arte de computer vision. Te recomiendo leer más acá.
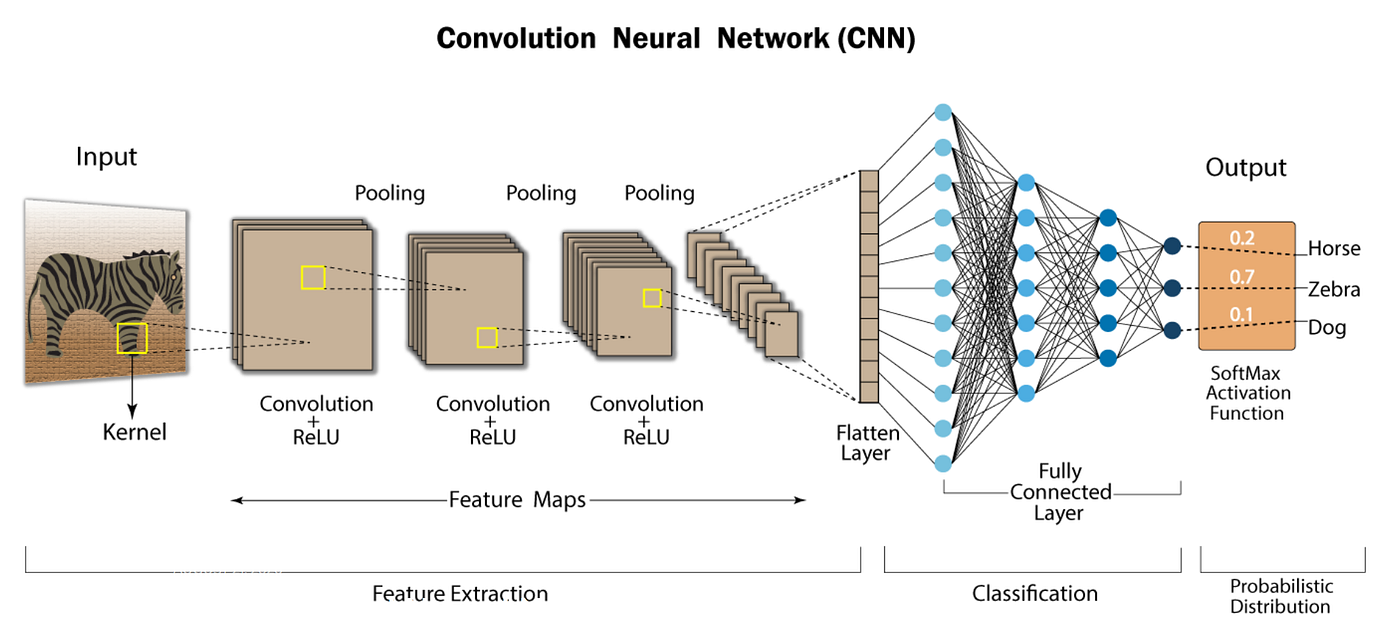
En este caso, utilizaremos como base alguna de las arquitecturas más conocidas pre-entrenadas. Luego, cambiaremos la parte de Clasificación, para que prediga entre las clases de nuestro propio caso de uso y entrenaremos en base a eso.
Debemos recordar que cuando uno entrena un modelo, lo que hace es ajustar ciertos pesos(parámetros) de forma que se reduzca la función de pérdida. En estas arquitecturas, existen millones de pesos a lo largo de la red. Debido a que el modelo está pre-entrenado, estos pesos ya han logrado capturar ciertos patrones, lo que facilitará la convergencia de nuestro modelo en el caso de uso que queremos: detectar razas de mascotas.
Intentar ajustar todos los pesos hará que nuestro modelo demore en converger y requiramos más recursos computacionales, además puede que no tengamos los mejores resultados. Una práctica común es congelar🥶 los pesos de la red pre-entrenada, y sólo ajustar los pesos de la parte de clasificación, y a veces algunas de las últimas capas. ¿ Porque sólo las últimas capas? Existen estudios que señalan que las últimas capas son aquellas que capturan los patrones más específicos/complejos de los casos de uso. Entonces si el modelo fue pre-entrenado en cebras, las últimas capas probablemente se fijarán en características específicas o más complejas de las cebras, mientras las primeras capas en características más generales de los animales. Esto es muy conveniente, nos gustaría conservar las características generales y ajustar aquellos pesos que detectan las características más específicas, para así detectar patrones complejos en nuestro propio caso de uso.
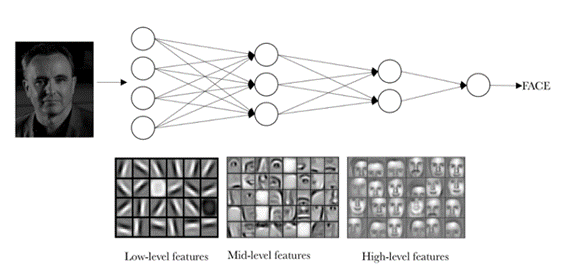
Para resumir, el procedimiento será el siguiente:
- Tomamos una arquitectura base (Backbone)
- Sustituimos la sección de clasificación por una propia.
- Congelamos los parámetros (pesos) de el modelo pre-entrenado.
- Entrenamos con nuestra data.
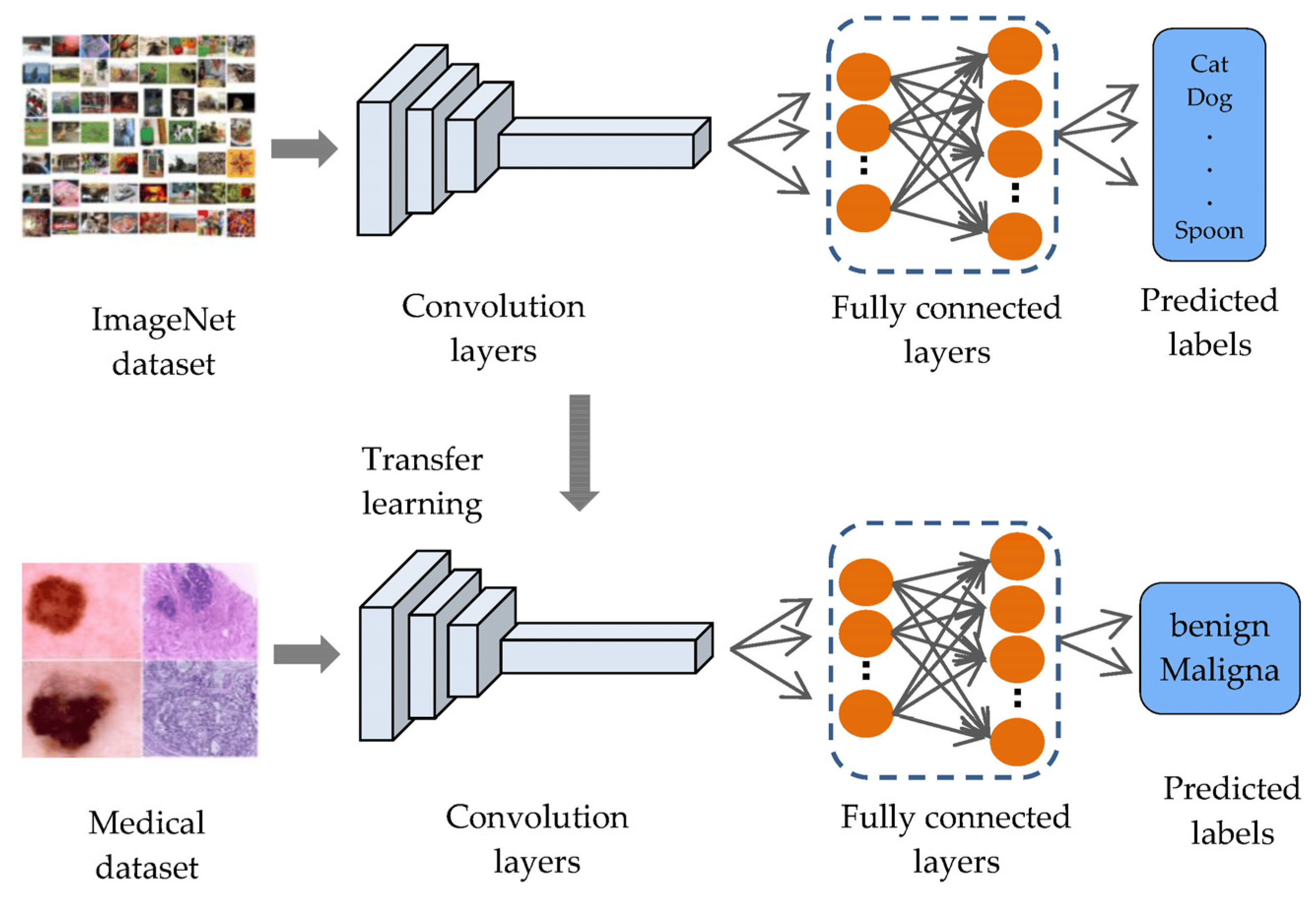
TIMM (pyTorch Image Models)
Una primera pregunta sería ¿Que modelo base utilizar? No hay una respuesta completamente teórica, creo que la respuesta simple sería: experimentar.
Existe un sin-fin de modelos base pre-entrenados, nosotros probaremos algunos de los más conocidos: EfficientNet, VGG, Inception y Resnet. Lo que haremos será entrenar estos modelos y quedarnos con aquél que nos entregue mejores resultados.
Para extraer los modelos pre-entrenados, utilizaremos timm: timm es una biblioteca de aprendizaje profundo creada por Ross Wightman y es una colección de modelos, capas, utilidades, optimizadores, programadores, cargadores de datos, aumentos y también scripts de entrenamiento/validación de computer vision SOTA models con capacidad para reproducir resultados de entrenamiento de ImageNet.
Básicamente es un repositorio de modelos pre-entrenados. Existen varios, Pytorch y tensorflow también tienen sus propios HUBs.
Traer un modelo pre-entrenado en timm es muy simple. Sólo debemos:
import timm
base_model = timm.create_model("model_name", pretrained = True, num_classes = len(CFG.idx_to_class))Al entregarle el parámetro num_classes. Timm automáticamente reemplaza la capa final de clasificación para que nos entregue predicciones acordes a nuestro caso de uso!
Aún así, para utilizar Pytorch Lightning debemos crear nuestra clase Model.
Antes de comenzar a crear nuestra clase modelo, actualicemos nuestra clase configuración con parámetros relacionados a ésta.
class CFG:
IMG_PATH = 'PATH/TO/IMAGES' # Ruta a imagenes
LABEL_PATH = '/PATH/TO/labels.csv' # Ruta a archivo de etiquetas
# Data
TEST_SIZE = 0.2
VAL_SIZE = 0.1
labels = pd.read_csv(LABEL_PATH) # leemos archivo de etiquetas
idx_to_class = dict(enumerate(labels.breed.unique())) # id -> clase
class_to_idx = {c:i for i,c in idx_to_class.items()} # clase -> id
# Model related
LEARNING_RATE = 0.001
MODEL = 'inception_v4' # timm name
PRETRAINED = TruePytorch Lightning ⚡️
Al igual que en Dataset, Pytorch requiere algunos métodos fundamentales en la creación de la clase Model. Estos son:
__init__(): Método que define las capas y otros componentes de un modelo.forward(): método donde se realiza el cálculo a través de la red. Tener en cuenta que podemos imprimir el modelo, o cualquiera de sus submódulos, para conocer su estructura.
Aún así, Pytorch Lightning necesita unos métodos extras:
training_step(): lógica de entrenamiento.configure_optimizers(): definir optimizadores y/o programadores LR.
Existen un montón de otros métodos importantes y útiles, los puedes ver acá.
- Comencemos con el paso 0:
class PetRecognitionModel(**L.LightningModule**):
def __init__(self):
super().__init__()
pass
def forward(self, x):
pass
def training_step(self, batch, batch_idx):
pass
def configure_optimizers(self):
passEn el código original, agregué otros métodos que utilicé, pero que sólo mostraré en este blog. Muchos de ellos eran para hacer la validación, testeo, predicción y logging.
- En cuanto al método
__init__(), inicializaremos la configuración, el modelo base y la métrica a utilizar:
class PetRecognitionModel(L.LightningModule):
def __init__(self, base_model, config):
super().__init__()
self.config = config
self.num_classes = len(self.config.idx_to_class)
self.metric = Accuracy(task="multiclass", num_classes=self.num_classes)
self.pretrained_model = base_model
def forward(self, x):
pass
def training_step(self, batch, batch_idx):
pass
def configure_optimizers(self):
passforward()el método forward es bastante sencillo, debemos definir como nuestro input pasará a través de nuestra arquitectura. Debido a que es sencilla, simplemente hará un paso por el modelo base, resultando:
class PetRecognitionModel(L.LightningModule):
def __init__(self, base_model, config):
super().__init__()
self.config = config
self.num_classes = len(self.config.idx_to_class)
self.metric = Accuracy(task="multiclass", num_classes=self.num_classes)
self.pretrained_model = base_model
def forward(self, x):
return self.pretrained_model(x)**
def training_step(self, batch, batch_idx):
pass
def configure_optimizers(self):
passtraining_step()puede ser un poco más complicado, la entrada de esta función será el batch de imágenes y labels, y debemos retornar la función de pérdida para ese batch.
class PetRecognitionModel(L.LightningModule):
def __init__(self, base_model, config):
super().__init__()
self.config = config
self.num_classes = len(self.config.idx_to_class)
self.metric = Accuracy(task="multiclass", num_classes=self.num_classes)
self.pretrained_model = base_model
def forward(self, x):
return self.pretrained_model(x)
def training_step(self, batch, batch_idx):
x,y = batch # dividimos el batch en data y labels
logits = self.forward(x) # la data pasa a través del modelo
loss = F.cross_entropy(logits, y) # Calculamos la función de pérdida
self.log_dict({'train_loss': loss}) # Logueamos el resultado
return loss # retornamos la pérdida
def configure_optimizers(self):
passPor ahora, no te preocupes de la linea self.log_dict({'train_loss': loss}), más adelante veremos para que es.
configure_optimizers(): Finalmente debemos definir nuestro optimizador, el cuál será bastante estándar: utilizaremos Adam con algún learning_rate dado.
from torch import optim
class PetRecognitionModel(L.LightningModule):
def __init__(self, base_model, config):
super().__init__()
self.config = config
self.num_classes = len(self.config.idx_to_class)
self.metric = Accuracy(task="multiclass", num_classes=self.num_classes)
self.pretrained_model = base_model
def forward(self, x):
return self.pretrained_model(x)
def training_step(self, batch, batch_idx):
x,y = batch # dividimos el batch en data y labels
logits = self.forward(x) # la data pasa a través del modelo
loss = F.cross_entropy(logits, y) # Calculamos la función de pérdida
self.log_dict({'train_loss': loss}) # Logueamos el resultado
return loss # retornamos la pérdida
def configure_optimizers(self):
optimizer = optim.Adam(self.parameters(), lr=self.config.LEARNING_RATE)
return {'optimizer': optimizer}Listo! ya tenemos nuestro modelo para entrenar. Si quieres ver la implementación completa, te recomiendo visitar el código en el repositorio de github. Aún así, ahora te mostraré el código final luego de agregarle métodos adicionales:
class PetRecognitionModel(L.LightningModule):
def __init__(self, base_model, config):
super().__init__()
self.config = config
self.num_classes = len(self.config.idx_to_class)
metric = Accuracy(task="multiclass", num_classes=self.num_classes)
self.train_acc = metric.clone()
self.val_acc = metric.clone()
self.test_acc = metric.clone()
self.training_step_outputs = []
self.validation_step_outputs = []
self.test_step_outputs = []
self.pretrained_model = base_model
def forward(self, x):
x = self.pretrained_model(x)
return x
def training_step(self, batch, batch_idx):
x,y = batch
logits = self.forward(x) # -> logits
loss = F.cross_entropy(logits, y)
self.log_dict({'train_loss': loss})
self.training_step_outputs.append({'loss': loss, 'logits': logits, 'y':y})
return loss
def on_train_epoch_end(self):
# Concat batches
outputs = self.training_step_outputs
logits = torch.cat([x['logits'] for x in outputs])
y = torch.cat([x['y'] for x in outputs])
self.train_acc(logits, y)
self.log_dict({
'train_acc': self.train_acc,
},
on_step = False,
on_epoch = True,
prog_bar = True)
self.training_step_outputs.clear()
def validation_step(self, batch, batch_idx):
x,y = batch
logits = self.forward(x)
loss = F.cross_entropy(logits, y)
self.log_dict({'val_loss': loss})
self.validation_step_outputs.append({'loss': loss, 'logits': logits, 'y':y})
return loss
def on_validation_epoch_end(self):
# Concat batches
outputs = self.validation_step_outputs
logits = torch.cat([x['logits'] for x in outputs])
y = torch.cat([x['y'] for x in outputs])
self.val_acc(logits, y)
self.log_dict({
'val_acc': self.val_acc,
},
on_step = False,
on_epoch = True,
prog_bar = True)
self.validation_step_outputs.clear()
def test_step(self, batch, batch_idx):
x,y = batch
logits = self.forward(x)
loss = F.cross_entropy(logits, y)
self.log_dict({'test_loss': loss})
self.test_step_outputs.append({'loss': loss, 'logits': logits, 'y':y})
return loss
def on_test_epoch_end(self):
# Concat batches
outputs = self.test_step_outputs
logits = torch.cat([x['logits'] for x in outputs])
y = torch.cat([x['y'] for x in outputs])
self.test_acc(logits, y)
self.log_dict({
'test_acc': self.test_acc,
},
on_step = False,
on_epoch = True,
prog_bar = True)
self.test_step_outputs.clear()
def predict_step(self, batch):
x, y = batch
return self.model(x, y)
def configure_optimizers(self):
optimizer = optim.Adam(self.parameters(), lr=self.config.LEARNING_RATE)
lr_scheduler = ReduceLROnPlateau(optimizer, mode = 'min', patience = 3)
lr_scheduler_dict = {
"scheduler": lr_scheduler,
"interval": "epoch",
"monitor": "val_loss",
}
return {'optimizer': optimizer, 'lr_scheduler': lr_scheduler_dict}La mayor parte de los métodos adicionales fueron hechos para poder ir monitoreando las métricas de el modelo, más adelante veremos por qué.
Finalmente, sólo nos falta instanciar el modelo.
model = PetRecognitionModel(base_model, config = CFG)Ahora, una parte importante será congelar aquellos parámetros que no queremos entrenar. Para esto, congelaremos todos los parámetros del modelo, y luego descongelaremos aquellos pertenecientes a las últimas capas:
def freeze_pretrained_layers(model, model_name):
'''Freeze all layers except the last layer(fc or classifier)'''
# Freeze All params
for param in model.parameters():
param.requires_grad = False
# Unfreeze Classifier Parameters EfficientNET
if model_name == 'efficientnet_b2':
model.pretrained_model.classifier.weight.requires_grad = True
model.pretrained_model.classifier.bias.requires_grad = True
# Unfreeze Classifier Parameters VGG19
elif model_name == 'vgg19_bn':
model.pretrained_model.head.fc.weight.requires_grad = True
model.pretrained_model.head.fc.bias.requires_grad = True
# Unfreeze Classifier Parameters Inception
elif model_name == 'inception_v4':
model.pretrained_model.last_linear.weight.requires_grad = True
model.pretrained_model.last_linear.bias.requires_grad = True
# Unfreeze Classifier Parameters Resnet
elif model_name == 'resnet50':
model.pretrained_model.fc.weight.requires_grad = True
model.pretrained_model.fc.bias.requires_grad = True
else:
raise Exception('Modelo no encontrado')Puedes notar que los nombres de las capas varian según el modelo. Ahora sólo debemos aplicar la función.
freeze_pretrained_layers(model, model_name = CFG.MODEL)4. Trainer
Alfin, ahora sólo nos queda entrenar. Esto será muy sencillo gracias al módulo Trainer de Pytorch Lightning, el cual se encargará de elaborar la rutina de entrenamiento en base a lo que definimos anteriormente.
Primero, definimos Trainer junto con las configuraciones que deseemos:
- Actualizamos clase CFG
class CFG:
IMG_PATH = 'PATH/TO/IMAGES' # Ruta a imagenes
LABEL_PATH = '/PATH/TO/labels.csv' # Ruta a archivo de etiquetas
# Data
TEST_SIZE = 0.2
VAL_SIZE = 0.1
labels = pd.read_csv(LABEL_PATH) # leemos archivo de etiquetas
idx_to_class = dict(enumerate(labels.breed.unique())) # id -> clase
class_to_idx = {c:i for i,c in idx_to_class.items()} # clase -> id
# Model related
LEARNING_RATE = 0.001
MODEL = 'inception_v4'
PRETRAINED = True
# Trainer
PRECISION = 16 # Float Precision
MIN_EPOCHS = 1 # Min epochs
MAX_EPOCHS = 3 # Max epochs
ACCELERATOR = 'gpu' # Device- Instanciamos el módulo Trainer
import lightning as L
trainer = L.Trainer(
accelerator=CFG.ACCELERATOR,
devices=1, # solo 1 device (gpu en nuestro caso)
min_epochs=CFG.MIN_EPOCHS,
max_epochs=CFG.MAX_EPOCHS,
precision=CFG.PRECISION,
)🚀 listo! ahora sólo nos queda ejecutar el ansiado .fit(). Pero aún falta algo importante ¿Como sabremos que modelo es mejor? Nos basaremos en la métrica Accuracy. Pero ¿donde la monitorearemos?
🐝 Weight and Biases Logging
Weight and Biases (W&B) es una plataforma que permite realizar un seguimiento, visualización y colaboración en proyectos de aprendizaje automático, lo que facilita el registro y el análisis de experimentos y modelos de Machine Learning.
En este caso, la utilizaremos para monitorear las métricas de nuestros modelos! Quizá en un futuro haga un blog de como utilizar esta maravillosa herramienta. En este caso es sencillo, sólo debemos inicializar Wandb logger, y comunicárselo a nuestro módulo Trainer.
- Actualizamos CFG con la info de nuestro proyecto en WandB
class CFG:
IMG_PATH = 'PATH/TO/IMAGES' # Ruta a imagenes
LABEL_PATH = '/PATH/TO/labels.csv' # Ruta a archivo de etiquetas
# Data
TEST_SIZE = 0.2
VAL_SIZE = 0.1
labels = pd.read_csv(LABEL_PATH) # leemos archivo de etiquetas
idx_to_class = dict(enumerate(labels.breed.unique())) # id -> clase
class_to_idx = {c:i for i,c in idx_to_class.items()} # clase -> id
# Model related
LEARNING_RATE = 0.001
MODEL = 'inception_v4'
PRETRAINED = True
# Trainer
PRECISION = 16 # Float Precision
MIN_EPOCHS = 1 # Min epochs
MAX_EPOCHS = 20 # Max epochs
ACCELERATOR = 'gpu' # Device
# Wandb related
WANDB_PROJECT = 'My-wandb-project'
WANDB_ENTITY = 'diegulio'- Instanciamos el logger
wandb_logger = WandbLogger(project = CFG.WANDB_PROJECT,
entity = CFG.WANDB_ENTITY,
name = f"{CFG.MODEL}_baseline", # exp name
log_model=False, # no guardar artefacto
config = wandb_config, # config
group = 'pretrained', # grupo
job_type = 'training') # tipo de trabajo- Agregamos el logger al Trainer
trainer = L.Trainer(
accelerator=CFG.ACCELERATOR,
devices=1,
min_epochs=CFG.MIN_EPOCHS,
max_epochs=CFG.MAX_EPOCHS,
precision=CFG.PRECISION,
logger = wandb_logger, # Agregamos el logger
)5. Fit
Ahora somos libres de entrenar!
trainer.fit(model, train_dataloader, val_dataloader)Veremos algo este estilo más una barrita de carga:
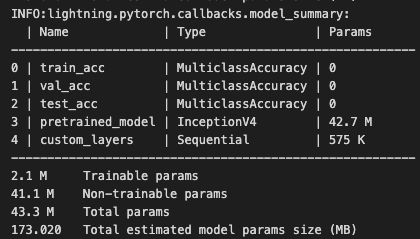
Observemos que la cantidad total de parámetros es de 43.3 Millones ! Aún así nosotros sólo entrenamos 2.1 Millones, y el resto lo congelamos 🥶
6. Evaluate
Con Pytorch Lightning la evaluación también es sencilla ya que previamente establecimos el método on_test_epoch_end(). Sólo debemos ejectuar:
trainer.test(model, test_dataloader)
Nota: El test accuracy mostrado acá fue con el modelo sin pre-entrenar. Podemos notar lo mal que le fue debido a que necesitaba más tiempo para converger.
🎯 Resultados
Todos los resultados los puedes ver en el panel de Wandb 🐝 !
Veamos el accuracy para los modelos baseline:
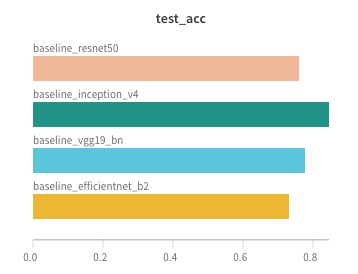
Vemos que Inception_v4 se queda con el trono 👑 (para este caso de uso, claro) con un accuracy de un 85% con sólo 3 epochs! Podemos ver un montón de otras métricas en Wandb, incluso podemos ver que tanto cómputo fue utilizado!
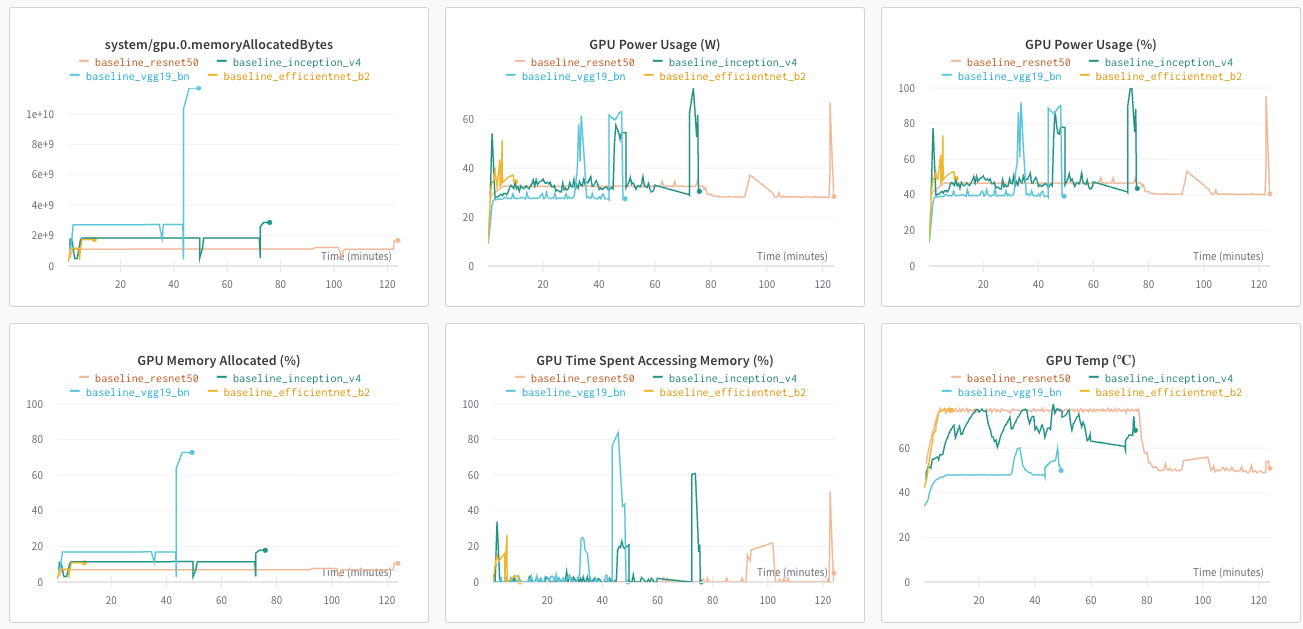
El hecho de que haya tenido un buen performance con sólo 3 iteraciones sobre el dataset, se lo debemos al uso de Transfer Learning 🧠.
En el panel, podrás ver que también hice otros experimentos, en donde varíe algunos parámetros, o agregué Data Augmentation (Ésta técnica es muy poderosa, permitiendo al modelo poder generalizar mejor agregándole variaciones a las imágenes.)
Luego de esto, el accuracy final fue de un 89%, lo cual es totalmente mejorable. En el repositorio de Github podrás ver el código final agregándole técnicas como:
- Data Augmentation
- Custom Layers
- Learning Scheduler
- Early Stopping
🧐 Front-End
Como siempre, no nos podemos quedar en puro código, es por esto que utilizaremos Gradio para poder crear una app utilizando nuestro modelo. Primero te dejaré el código, el cual es bastante sencillo gracias a Gradio!
import gradio as gr
import torch
from torchvision import transforms
from app.backbone import Backbone
from app.config import CFG
from app.model import PetClassificationModel
# Cargamos modelos
backbone = Backbone(CFG.MODEL, len(CFG.idx_to_class), pretrained=CFG.PRETRAINED)
model = PetClassificationModel(base_model=backbone.model, config=CFG)
model.load_state_dict(torch.load("models/best_model.pt"))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Modo evaluacion
model.eval()
model.to(device)
# Funcion que cambia tamaño de la imagen de entrada
pred_transforms = transforms.Compose(
[
transforms.Resize(CFG.IMG_SIZE),
transforms.ToTensor(),
]
)
# Función de predicción
def predict(x):
x = pred_transforms(x).unsqueeze(0) # transform and batched
x = x.to(device)
with torch.no_grad():
prediction = torch.nn.functional.softmax(model(x)[0], dim=0)
confidences = {
CFG.idx_to_class[i]: float(prediction[i])
for i in range(len(CFG.idx_to_class))
}
return confidences
# Interfaz Gradio
gr.Interface(
fn=predict,
title="Breed Classifier 🐶🧡🐱",
description="Clasifica una imagen entre: 120 razas, gato o ninguno!",
inputs=gr.Image(type="pil"),
outputs=gr.Label(num_top_classes=5),
examples=[
"statics/pug.jpg",
"statics/poodle.jpg",
"statics/cat.jpg",
"statics/no.jpg",
],
).launch()Finalmente, nuestra aplicación queda como:
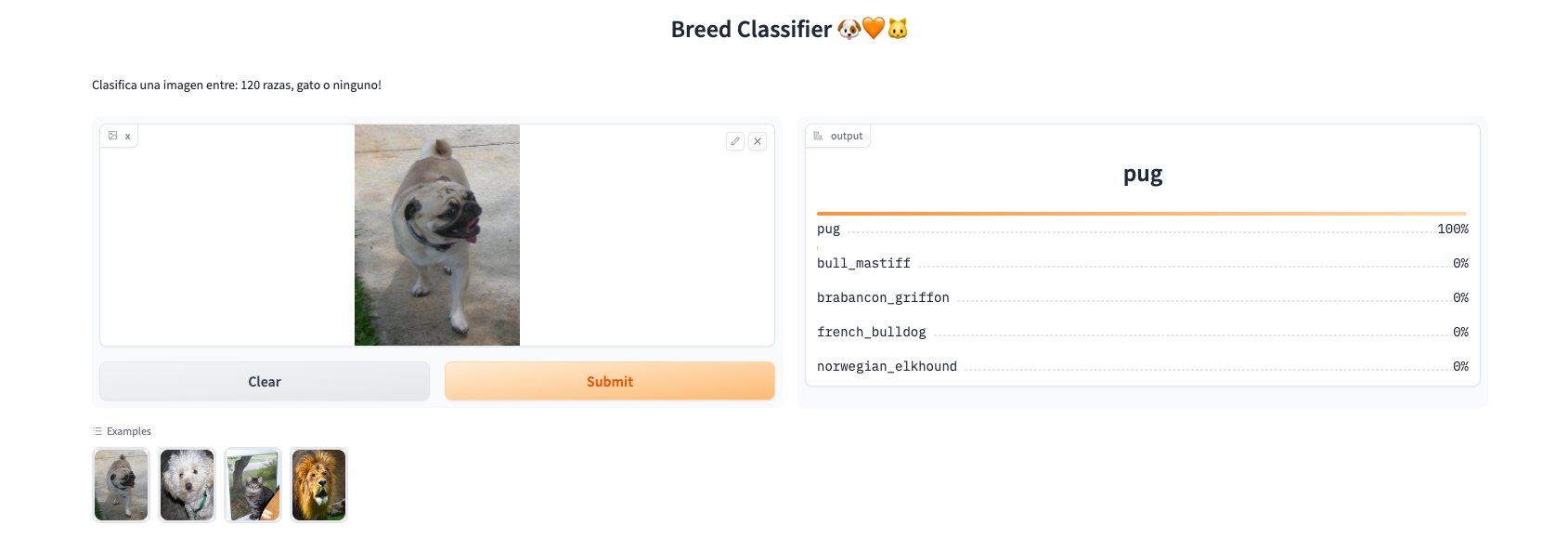
🚀 Próximos Pasos
Para mejorar la solución podriamos intentar distintas técnicas, algunas de estas son:
- Unfreeze more layers: Descongelar más capas, esto suele ser efectivo cuando la tarea para la cual fue entrenado el modelo base es muy distinta a la tarea para la cual estamos trabajando.
- Más Data Augmentation: Si nuestro modelo generaliza mal, creando otros tipos de variaciones puede mejorar el performance de nuestro modelo
- Agregar más layers: Podemos agregar más capas en la parte de clasificación, así pudiendo capturar patrones más complejos. Esto puede ser efectivo en casos donde tu modelo esté sufriendo de Underfitting.
- Data Oriented: En los datos, me di cuenta que hay algunas imágenes mal etiquetadas, esto puede provocar pérdida de performance. Un buen enfoque podría ser dedicarse a mejorar la calidad de los datos. Recordemos que si basura entra, basura sale.
- Transformers: Probar los nuevos modelos de computer vision basados en transformers (ViT).
🥳 Conclusión
En este blog hemos abordado un desafío de clasificación de imágenes que abarca 120 razas de perros, la categoría de gato y la opción “No detectado”. Hemos demostrado cómo PyTorch Lightning y la técnica de transfer learning pueden simplificar drásticamente el proceso de desarrollo y entrenamiento de modelos de Convolutional Neural Networks (CNN) preentrenados. Este enfoque nos ha permitido aprovechar el conocimiento previo de modelos preentrenados para resolver un problema altamente complejo y ha allanado el camino hacia soluciones efectivas y eficientes en tareas de clasificación de imágenes. Con estas herramientas a nuestro alcance, estamos preparados para abordar desafíos aún mayores y avanzar en la investigación y aplicaciones del aprendizaje profundo en el mundo de la visión por computadora.