LLM CV Reviewer
![]()
Tópico: LLM - Chat ❤️ Data
En mi último post: Iniciando en LLM: Crea tu primera aplicación con LangChain y ChatGPT pudimos observar las capacidades que podemos aprovechar de los Large Language Models (LLM).😲 Démos un vistazo a que aprendimos en el blog pasado:
- Introducción LLM
- OpenAI ChatGPT Model
- Chat Model
- Text Model
- Lanchain
- Prompts
- Chains
- Gradio
TLDR (too long to read): En ese blog creamos una aplicación con una interfaz gráfica utilizando Gradio en donde se le permitía al usuario ingresar una comida y obtener tanto la receta como información de los ingredientes. Para esto utilizamos los poderes de los modelos brindados por OpenAI 🤖 y orquestando todo con las facilidades que nos entrega Langchain 🦜⛓️. La arquitectura fue “simple” 🙄, utilizamos una cadena de LLMs en donde cada uno era acompañado por un prompt template.
Un punto importante a mencionar es que la información utilizada para obtener los ingredientes provenía de un montón de información esparcida por internet con la cual fue entrenado el modelo de OpenAI. Dicho esto, existirán muchas ocasiones en donde nos gustaría que nuestros modelos puedan consultar nuestra propia información! Imagina que te hubiese gustado que el modelo solo responda con recetas de tu país 🥘
Adivina que! En este post veremos como resolver esto pero sin comida, no queremos quedar satisfechos de aprender! 📚
📁 Motivación: Revisión de Currículum
En una de las empresas que trabajé solía entrevistar a los futuros practicantes y memoristas que se unirían al equipo (tarea que disfrutaba mucho, por cierto). Lamentablemente mi memoria me suele fallar y a veces recordaba que tenía la entrevista unos minutos antes por lo que no alcanzaba a leer el curriculum del candidato (cosa importante). Este problema lo solucionaba leyendo el curriculum mientras entrevistaba al candidato o candidata pero esto generaba poca fluidez en mi conversación y a veces pérdida de información de lo que la candidata me decía. Esto era sumamente riesgoso ya que encuentro importante escuchar con atención las experiencias de los candidatos, pero tristemente mi multitasking me fallaba.
Entonces ahora pensé, que entretenido seria tener un asistente que me ayudara a leer los curriculums de los candidatos! Y que mejor si este asistente es un robot (así puedo explotarlo muajaj 😈)
🧠 Solución: Utilizar LLM para “chatear” con los CV entregados por los candidatos.
Como siempre, ésto sólo fue una excusa para aprender sobre como conectar mis documentos con un LLM.
Cabe mencionar que esta solución es muy escalable, imaginemos utilizarla para ayudar a una empresa de recursos humanos a entrevistar multiples candidatos a la vez, obteniendo comparaciones, estimaciones de fit con la empresa, etc.
👨🏾💻 Demo
A modo de motivación, te dejo un simple demo de lo que construiremos! 
🔨 Tool Path: Que utilizaremos
A continuación les dejo las herramientas que utilizaremos en este post:
- 🌴 PaLM API: LLM entrenado por Google AI
- 🦜⛓️ LangChain: Para poder comunicarme de manera fácil con la API de PaLM, además de aprovechar un montón de los facilitadores que tiene para construir herramientas basadas en LLM
- 🐍 Python: Lenguaje de Programación
- 👑 Streamlit: Framework para crear interfaz de usuario
💭 Concept Path: Que aprenderemos
A continuación algunos de los conceptos que aprenderemos:
- LLM: Modelo de lenguaje
- Document Management: Como procesamos documentos para un LLM
- Embeddings: Como traducimos texto (de documentos) a algo entendible para un LLM
- Vector Stores: Donde almacenamos los embeddings de los textos
- Retrievers: De que forma le entregamos el documento a un LLM
♟️ Estrategia: Como abordamos
Creo que en esta sección tendremos muuuuucho que abordar 🫠. Primero entendamos como los LLM suelen usar la información de los documentos, y luego desentrañaremos las oscuras técnicas que existen para llevar a cabo esto.
Document As Context
Desde una vista general, los LLM utilizan la información de documentos como contexto. Imaginemos tenemos un documento de texto (un PDF) bastante simple que contiene algo como:
Diego tiene 25 años, es Ingeniero Civil Industrial, le gusta ver animé, jugar videojuegos, ir al gimnasio y jugar pádel.
Luego, si un usuario pregunta:
Si usamos el LLM como tal, sin entregarle el documento, el modelo respondería algo como:
Quizá exageré un poco, pero se entiende. El LLM no tiene la información del documento que necesito considere. Como mencioné anteriormente, ésto se soluciona agregando la información como contexto en el prompt, quedando algo por el estilo:
Fijemonos que se le agregaron tanto instrucciones y contexto. Dejando que luego de eso el LLM responda la pregunta deseada tal y como lo preguntó el/la usuaria.
Hasta ahora bastante sencillo cierto? Apuesto a que imaginabas que por detrás se volvía a entrenar el modelo agregándole preguntas y respuestas del documento … blablabla. no? porque yo si lo pensaba 😆
Veamos un diagrama de lo que tendríamos por el momento:
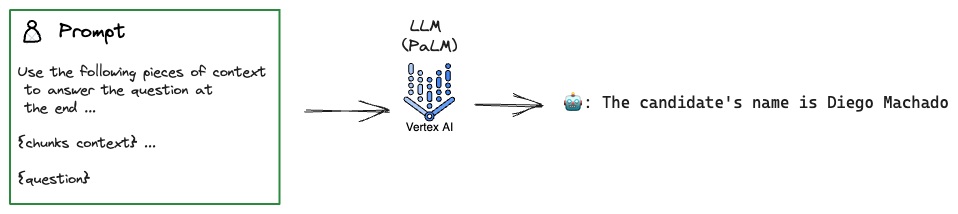
Hasta ahora todo bien, pero no debemos olvidar una limitante importante en los prompt de los LLM. El famoso context_length ! Este canalla (como diría mi abuela 👵🏼) nos restringe la cantidad de caracteres, tokens, etc que podemos ingresar en el prompt. Entonces cuando tenemos documentos muy grandes y con gran cantidad de caracteres, que hacemos?
Data Connection
Ya sabemos que suponiendo un documento tan grande que sobrepase el context_lenght no podremos agregar esta información como contexto a nuestro prompt. Una opción válida sería simplemente tomar un extracto aleatorio del documento e insertarlo como contexto. Lamentablemente será muy probable que el contexto adecuado para responder la pregunta del usuario no se encuentre en el extracto aleatorio.
💡 Una mejor idea seria extraer partes del documento que se relacionen con la pregunta. Entonces la estrategia queda como:
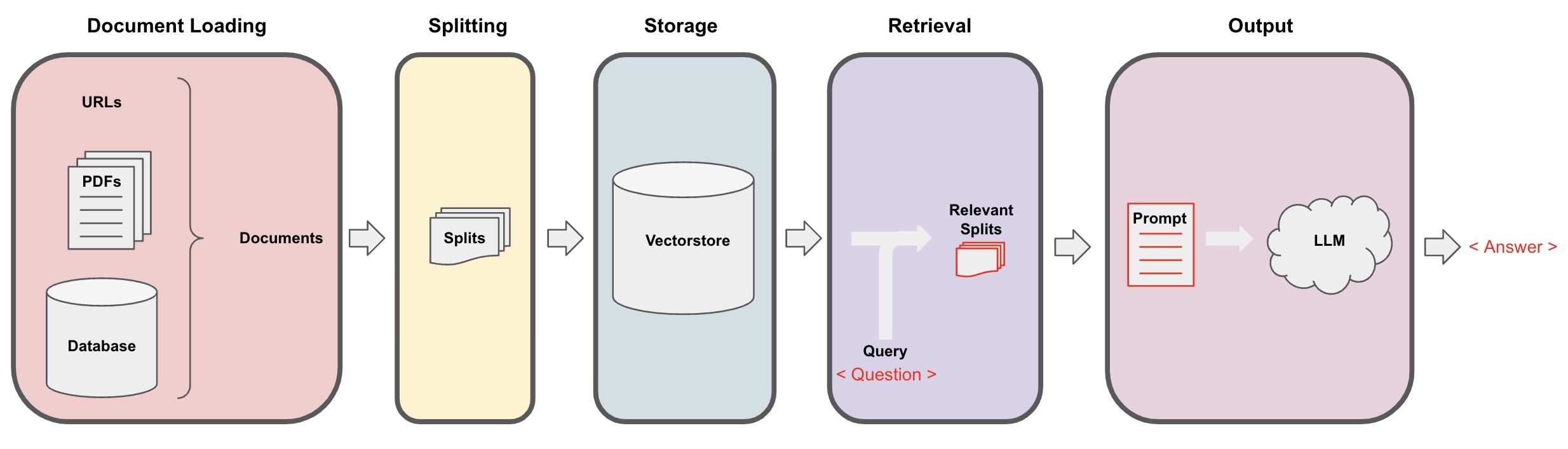
- Load Documents: Cargar los documentos
- Split Documents: Dividir los documentos en piezas de texto
- Embedding: Extraer features de las piezas de texto
- Vector Store: Guardar features en una base de datos para utilizarlo después.
Acá les presento un diagrama que simboliza este proceso:
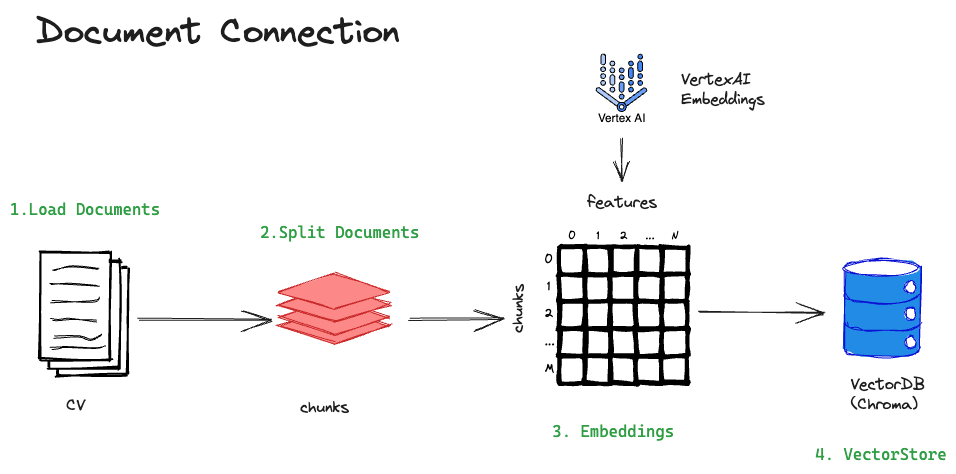
El objetivo final es poder representar cada pieza (chunk) de texto de forma semántica, para así poder hacer la relación con la pregunta del usuario, y decidir que chunks incluir en el prompt final. Ahora naveguemos un poco por cada paso:
1. Load Documents
Esta etapa es bastante simple, sólo requiere poder pasar los documentos a texto. Langchain posee una gran variedad de métodos para hacer esto, acá te dejo la documentación.
En nuestro caso es poder tomar un CV en PDF y extraer el texto de este. También podemos extraer texto de DataFrames, Json, Latex, Wikipedia, etc.
2. Split Documents
Existen varias formas para dividir documentos, puede ser por caracteres, por elementos Markdowns, tokens, etc. Creo que no vale la pena que yo te lo explique cuando existe una buena documentación para aquello.
Acá hay dos conceptos que pueden ser importantes, que son el tamaño del chunk chunk_size y el tamaño del overlap en los distintos chunks overlap_size. Si el tamaño del chunk es muy pequeño entonces puede ser difícil extraer un buen contexto, pero si por el contrario es muy grande puede que estemos extrayendo información poco valiosa, y además arriesgándonos podemos sobrepasar el context_length.
En general, los divisores de texto funcionan de la siguiente manera:
- Dividir el texto en pequeños fragmentos semánticamente significativos (a menudo oraciones).
- Comenzar a combinar estos pequeños fragmentos en un fragmento más grande hasta que alcance un cierto tamaño
chunk_size(según lo medido por alguna función). - Una vez que alcance ese tamaño, hace que ese fragmento sea su propio fragmento de texto y luego comience a crear un nuevo fragmento de texto con algo de superposición
overlap_size(para mantener el contexto entre los fragmentos).
3. Embeddings
El concepto de Embeddings es muy importante en Machine Learning en general. Siendo muy utilizados cuando hablamos de textos. Puedes ver como en el post Identificando desastres en Twitter con NLP utilizamos embeddings para representar texto de forma numérica (usando vectores en este caso).
Podría escribir un blog entero sobre esto, pero creo que encontrarás mejor información en internet. Acá te dejo con un starter que puede ser la vieja y confiable Wikipedia.
Creo que sólo nos basta con saber que podemos representar tanto palabras, carácteres, sentencias, documentos, etc con vectores. Además podemos calcular medidas de similaridad entre estos utilizando operaciones vectoriales, como el conocido producto punto, o calculando el coseno del ángulo entre los vectores. Vuelvo a repetir que este concepto es muy importante y que si lo desconoces debes ya ir a darle unas vueltas! 🚀
4. Vector Stores
Imaginemos que tenemos este gran documento, el cual dividimos en distintos chunks y transformamos a vectores. Muchas veces el/los documentos serán tan grandes que ni siquiera cabrán en la memoria de nuestro computador (en la RAM). Es por esto que se utilizan los llamados Vector Stores, que son almacenamientos de embeddings. Acá podremos guardar cada palabra, sentecia, documento con su respectivo embedding, para luego simplemente consultar esta base de datos y no tener que calcular el embedding todo el tiempo.
Existen vector stores que almacenan esta información en la nube, podrás encontrar compañías que ofrecen estos servicios como Pinecone, Weviate, GCP con Matching Engine. Hay otros como FAISS por Facebook AI e incluso algunos que almacenan la información en la memoria RAM (si es posible) como Chroma.
Además, estas herramientas no sólo ofrecen almacenar esta información, si no que también calcular la relación semántica entre alguna frase, pregunta, prompt y los vectores presentes en la base datos de forma muy eficiente.
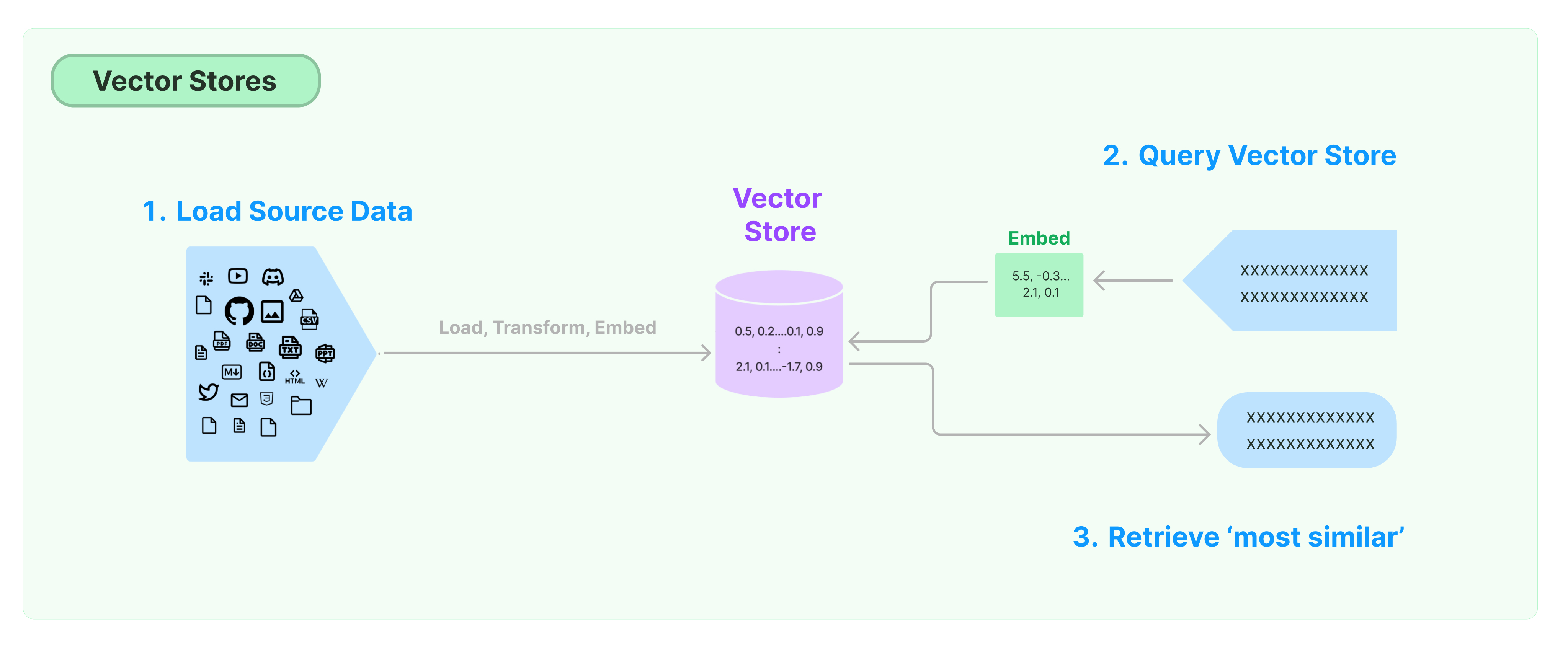
Otro punto importante a considerar acá son los distintos métodos disponibles para calcular la similaridad entre la query y los vectores para obtener aquellos más similares.
Retrievers
Volvamos al diagrama que teniamos hace un rato:
Habiamos quedado estancados con el hecho de que algunos documentos podrian no caber en el contexto entregado al prompt debidos al limitado context_length.
Ahora dividimos el documento, los convertimos a vectores, los almacenamos y además tenemos técnicas para calcular la similaridad entre una query y los distintos chunks.
Entonces nuestra misión se resume a: En base a una pregunta, obtener las piezas de texto (chunks) más relevantes para incluirlos en el prompt final.
Para entenderlo mejor, consideremos como ejemplo nuestro caso de uso para chatear con los curriculums, tenemos la pregunta del usuario:
E imaginemos que tenemos un CV muy grande (poco recomendable), algo del estilo:
Nombre: Diego Machado
Edad: 25 años
Hobbies: Ir al gym, jugar pádel, jugar videojuegos
.... texto .... bla bla ..
Diego Machado estudió en .... bla bla
.... texto ...
Trabajó 1 año en ... luego trabajó en ...
Sus habilidades son ....
.... texto .....
.... mucho texto ...Podemos ver que en este texto se encuentre la respuesta al prompt de manera explícita en dos ocasiones. Lo que esperamos que logre el procedimiento mostrado en Data Connection será obtener los chunks de texto:
Nombre: Diego Machado
Edad: 25 años
Hobbies: Ir al gym, jugar pádel, jugar videojuegos y
Diego Machado estudió en .... bla bla
.... texto ... Así, respetamos el chunk_size y además le entregamos los documentos más relevantes al LLM en base al calculo de similaridad entre la pregunta “What is the candidate name?” y los distintos chunks.
Entonces ahora tenemos un buen contexto que no incumple alguna norma, por lo que el prompt final se transforma en:
y lo que esperamos que suceda será una respuesta del estilo:
Y listo! Asi podemos resolver el problema de los documentos largos. Entonces el diagrama anterior resulta en:
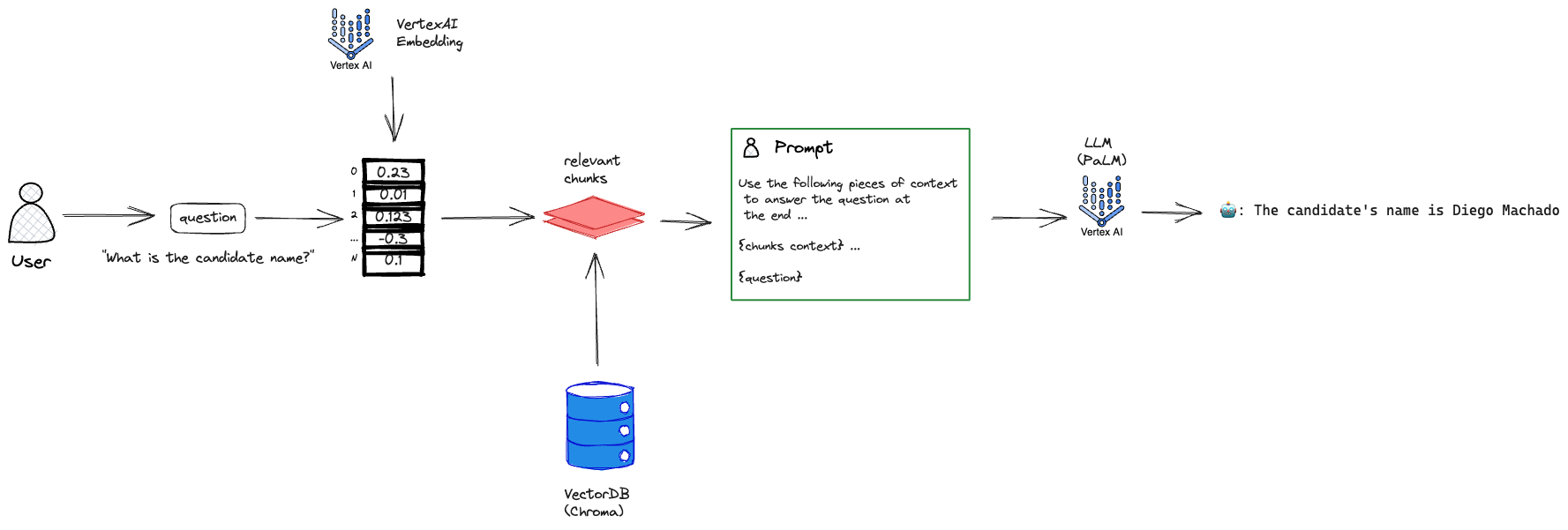
Chain Documents
ALTO AHÍ! Aún falta algo. Si nos fijamos bien, lo que hice con los chunks de texto relevantes fue simplemente concatenarlos! uno sobre el otro!
Nombre: Diego Machado
Edad: 25 años
Hobbies: Ir al gym, jugar pádel, jugar videojuegos
Diego Machado estudió en .... bla bla
.... texto ...A esto se le llama stuff. Pero también existen distintas metodologías para hacer esto de forma muy eficiente y robusta. Algunas de ellas incluso utilizan LLM auxiliares para refinar este contexto! Te invito a leer más sobre eso acá.
Fiuf! Creo que eso sería “todo”, por último te dejo un diagrama general, el cual muestra todos los elementos utilizados:
🧠 Prototyping: Code Time!
Ahora es el momento de llevar todas estas ideas al código.
Revisitemos el proceso que necesitamos:
- Load Document: Cargar Curriculum
- Splitting: Dividir información en chunks
- Vector Store: Almacenamos embeddings
- Create Conversational Retrieval Chain: Esto es básicamente la creación del bot.
1. Load Document
Langchain tiene integraciones con un montón de tipos de documentos, para nuestro caso, en donde suponemos curriculums en pdf, debemos cargarlo de la siguiente forma:
from langchain.document_loaders import PyPDFLoader
# Langchain loader
loader = PyPDFLoader("../docs/CV_DMV.pdf")
# Load pages
pages = loader.load()Importante notar que también podemos extraer metadata:
pages[0].metadata
# {'source': '../docs/CV_DMV.pdf', 'page': 0}2. Splitting documents
En este caso utilizaremos el método Recursive Character Text Splitter.
Este separador de texto es el recomendado para texto genérico. Se parametriza mediante una lista de caracteres. Se Intenta dividirlos en orden hasta que los trozos sean lo suficientemente pequeños. La lista predeterminada es [“”, “”, ” “,””]. Esto tiene el efecto de tratar de mantener todos los párrafos (y luego las oraciones y luego las palabras) juntos el mayor tiempo posible, ya que genéricamente parecerían ser los fragmentos de texto más relacionados semánticamente.
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
chunk_size = 1000,
chunk_overlap = 100,
)
texts = text_splitter.split_documents(pages)Notemos que acá aparecen los parámetros mencionados anteriormente: chunk_size, chunk_overlap
Lo que esta función retorna es una lista de Documents
texts = [
Document(page_content='Nombre:DiegoMachadoEdad:25años..', metadata={..}),
Document(page_content='..texto..', metadata={..}),
Document(page_content='DiegoMachadoestudióen....', metadata={..}),
]3. Vector Store
Ahora creamos nuestro vector store, en este caso Chroma. Notar que debemos ingresar como parámetro la función de embeddings a utilizar. En este caso utilizamos Vertex AI Embeddings
from langchain.vectorstores import Chroma
from langchain.llms import VertexAI
from langchain.embeddings import VertexAIEmbeddings
# Embeddings fn
embeddings = VertexAIEmbeddings(project='gcp-project')
# Persist Directory
persist_directory = 'docs/chroma/'
# Vector db
vectordb = Chroma.from_documents(
documents=texts,
embedding=embeddings,
persist_directory=persist_directory
)Podemos utilizar persist directory si queremos almacenar el vector store en nuestro local, para asi no tener que cargarlo cada vez que lo instanciamos:
vectordb.persist()Utilizando el vector store podemos ocupar su funcionalidad de similarity_search para encontrar los chunks más similares a una query en particular:
# Test embeddings
question = "What is the name of the candidate?"
docs = vectordb.similarity_search(question,k=2)
print(docs[0].page_content[:300]) # Solo imprimiremos los primeros 300 caracteres del primer documentoDIEGOMACHADO
/_4782ndAugust1997 /_475dmachadovz@gmail.com /phone+56950917953 /map_markerSantiago,Chile
/linkedinwww.linkedin.com/in/DiegulioMachado /githubhttps://github.com/diegulio ὑ7diegulio.github.io
BRIEFDESCRIPTION
Industrialengineeringgraduatedwitha
master’sdegreeinengineeringsciences.
PassioPodemos notar que el nombre del candidato aparece en el documento más similar a la query! esto cumple con nuestras expectativas 😎
Conversational Retrieval Chain
Ahora es donde podemos crear una cadena personalizada que tome el contexto según la query, que cree el prompt final y que incluso vaya conservando la memoria.
La buena noticia es que Langchain ya tiene una cadena pre-construida que se encarga de todo esto! por lo que utilizarlo es muy fácil:
from langchain.memory import ConversationBufferMemory
# Primero instanciamos el tipo de memoria
memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True
)Esta cadena personalizada necesita 3 cosas: un LLM, el retriever y la memoria. En este caso utilizaremos el retriever base de Chroma, pero recuerda que podemos plantear otros!
from langchain.chains import ConversationalRetrievalChain
# Instanciamos LLM
llm = VertexAI(project_id = 'gcp-project')
# Retriever
retriever=vectordb.as_retriever()
qa = ConversationalRetrievalChain.from_llm(
llm,
retriever=retriever,
memory=memory
)Y listo! la parte del código parece ser lo más sencillo, todo gracias al framework Langchain 🦜⛓️❤️
Ahora podemos probarlo:
question = "Does the candidate has been teacher assistant?"
result = qa({"question": question}){'question': 'Does the candidate has been teacher assistant?',
'chat_history': [HumanMessage(content='Does the candidate has been teacher assistant?', additional_kwargs={}, example=False),
AIMessage(content='Yes, the candidate has been a teacher assistant.', additional_kwargs={}, example=False)],
'answer': 'Yes, the candidate has been a teacher assistant.'}Si volvemos a preguntar, en el chat_history se irá guardando automáticamente toda la info del chat, por lo que nuestro bot se acordará de preguntas anteriores ! 🤖
question = "In which universities?"
result = qa({"question": question}){'question': 'In which universities?',
'chat_history': [HumanMessage(content='Does the candidate has been teacher assistant?', additional_kwargs={}, example=False),
AIMessage(content='Yes, the candidate has been a teacher assistant.', additional_kwargs={}, example=False),
HumanMessage(content='In which universities?', additional_kwargs={}, example=False),
AIMessage(content='The candidate has been a teacher assistant at Universidad de Santiago and Universidad Adolfo Ibañez.', additional_kwargs={}, example=False)],
'answer': 'The candidate has been a teacher assistant at Universidad de Santiago and Universidad Adolfo Ibañez.'}🧐 Front-End
Como siempre, nuestra aplicación no puede quedar sólo en palabras. En esta ocasión utilizamos los nuevos componentes de streamlit para chat!
# Input de usuario
prompt = st.chat_input("Ask something")# Respuesta (Puede ser de usuario, assistant, system o más)
with st.chat_message("user", avatar=user_avatar):
st.write(message.content)Con estos elementos es que podemos construir algo así:
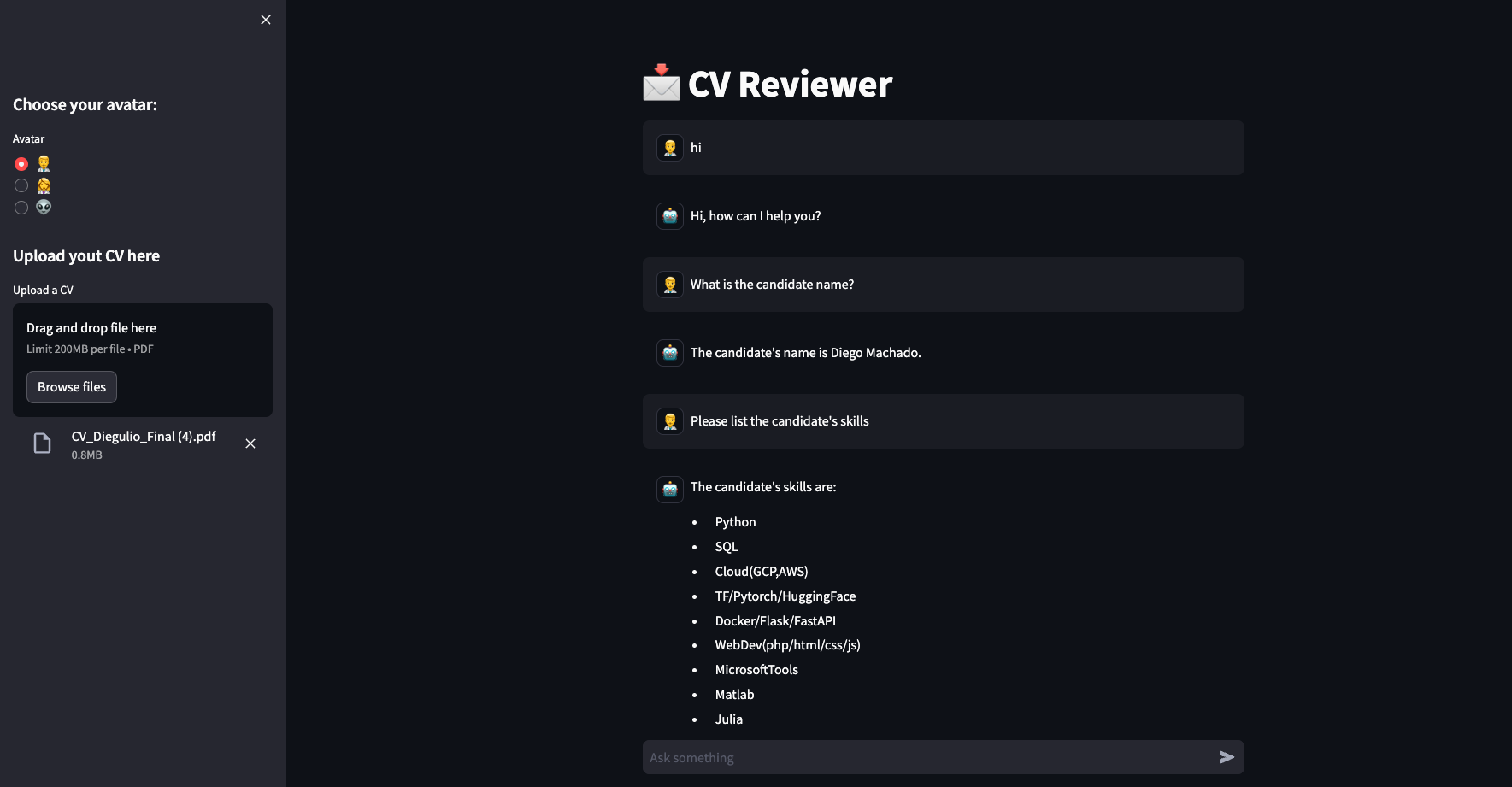
Para ver el código utilizado para construir esta aplicación puedes visitar el repositorio.
🚀 Próximos Pasos
Como mencioné anteriormente, esta solución puede mejorarse mucho más. Acá una lluvia de ideas:
- Verificar que lo que se suba sea un CV
- Aceptar más tipos de documentos
- Probar más tipos de Retrievers
- Probar más tipos de Documents Chains
- Aceptar múltiples CVs y poder comparar
🥳 Conclusión
En conclusión, en este blog hemos explorado cómo aprovechar los Large Language Models (LLM) para crear una aplicación de chat que interactúa con documentos. Utilizamos el modelo PaLM de VertexAI junto con LangChain para orquestar toda la funcionalidad. Nuestro enfoque fue utilizar LLMs para leer y responder preguntas sobre currículums.
Aprendimos sobre la importancia de los embeddings para representar el texto en forma numérica, así como los Vector Stores para almacenar y recuperar eficientemente estos embeddings. También descubrimos cómo resolver el problema de documentos largos utilizando técnicas de división, embeddings y retrievers para mantener el contexto relevante en los prompts.
Nuestra aplicación de chat con currículums puede ser ampliada para otros usos y aplicaciones, como asistentes para entrevistas de recursos humanos o cualquier caso donde se necesite interactuar con documentos de manera eficiente. Además, se pueden explorar otras metodologías de retrievers y document chains para mejorar aún más la experiencia.
En definitiva, esta exploración ha sido solo el comienzo, y el potencial de los Large Language Models junto con herramientas como LangChain es emocionante. Con estos avances, podemos crear aplicaciones más inteligentes y personalizadas, que nos ayuden en tareas complejas y mejoren nuestra interacción con la información.